En este artículo explicamos cómo diseñar e implementar un sistema de backup y restore consistente para bases de datos distribuidas usadas en productos de IA. A partir de un caso real con Qdrant, mostramos cómo agrupar snapshots, orquestar backups en múltiples nodos y asegurar restauraciones confiables incluso cuando la configuración del clúster cambia. El enfoque está orientado a equipos que construyen infraestructura de datos robusta, escalable y preparada para fallos.

A medida que las empresas adoptan bases de datos vectoriales para casos como búsqueda semántica, asistentes con IA, RAG y sistemas de recomendación, surge un reto clave: cómo garantizar la continuidad operativa cuando el sistema crece, se distribuye y falla. En Meetlabs trabajamos con arquitecturas de datos modernas donde la disponibilidad, consistencia y escalabilidad no son opcionales. En este artículo explicamos cómo abordar el backup y la restauración de bases de datos vectoriales en clústeres distribuidos, y cómo diseñar una solución que permita recuperar información de forma rápida, consistente y automatizada, incluso en escenarios de fallos.
Al construir productos basados en IA, especialmente aquellos que utilizan embeddings, aparece un desafío recurrente: manejar grandes volúmenes de datos vectoriales de forma confiable. Textos, imágenes, comportamiento de usuarios y otras señales se transforman en representaciones numéricas, en este caso los vectores que deben almacenarse, buscarse y filtrarse de manera eficiente.
Aquí es donde entran las bases de datos vectoriales. En Meetlabs, Qdrant es una de las tecnologías que utilizamos para habilitar flujos de búsqueda por similitud y Retrieval-Augmented Generation (RAG), cada vez más comunes en sistemas de IA modernos.
Qdrant es una base de datos vectorial optimizada para búsquedas de similitud en espacios de alta dimensionalidad. En lugar de trabajar únicamente con filas y columnas, se centra en vectores y en la distancia matemática entre ellos.
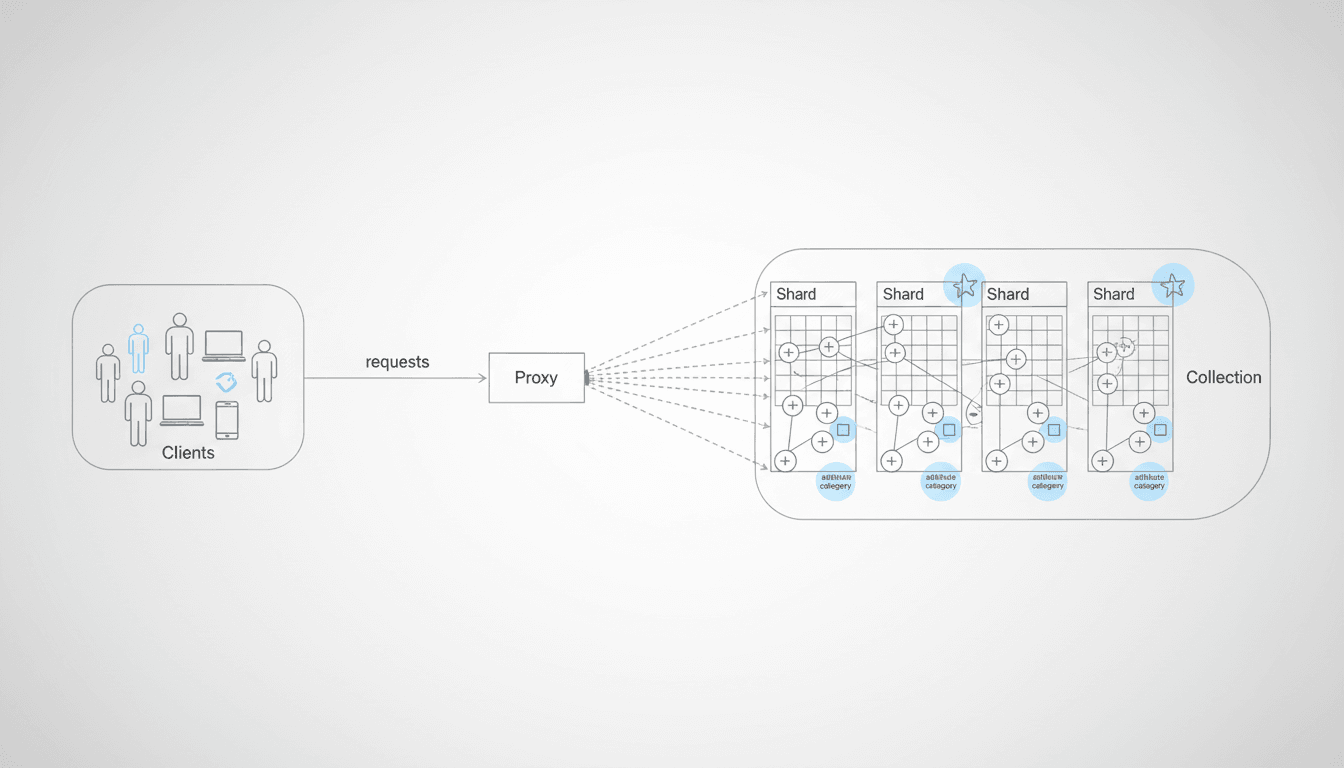
A nivel lógico, Qdrant estructura los datos de la siguiente forma:
Este diseño permite combinar búsquedas semánticas por similitud con filtros basados en metadatos, logrando resultados más precisos sin perder contexto.
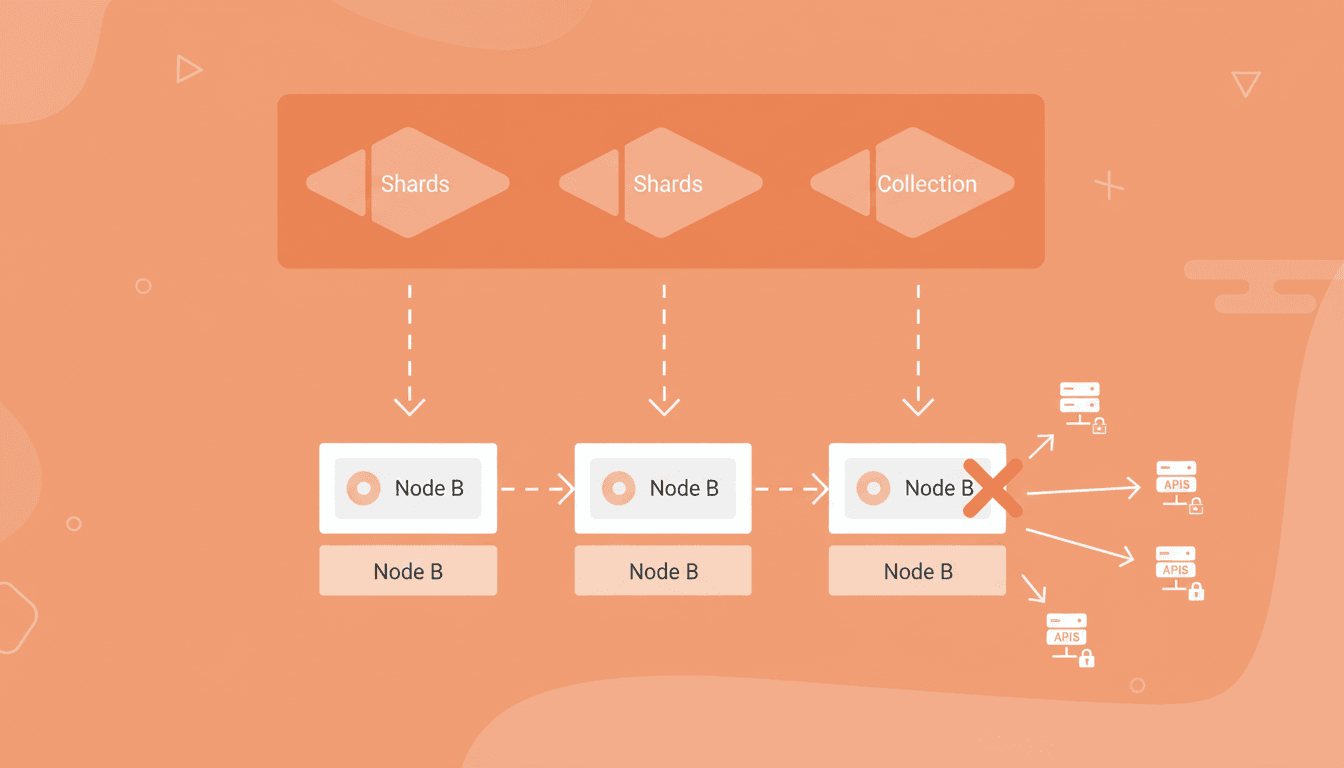
A medida que los datos crecen, Qdrant puede operar en modo distribuido. Las colecciones se dividen automáticamente en shards, que se distribuyen entre distintos nodos mediante hashing consistente.
En entornos modernos, estos nodos suelen desplegarse como pods en Kubernetes, lo que aporta flexibilidad, pero también introduce complejidad operativa cuando el número de nodos cambia.
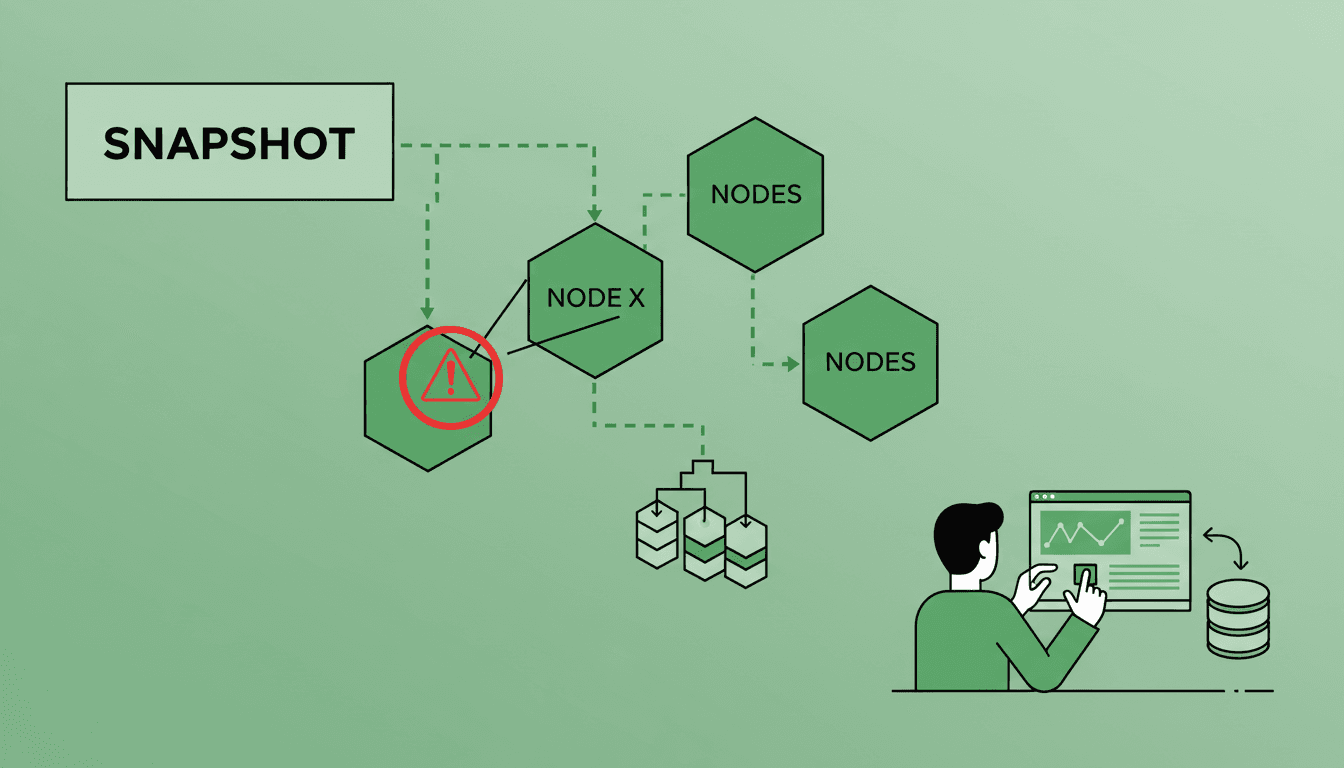
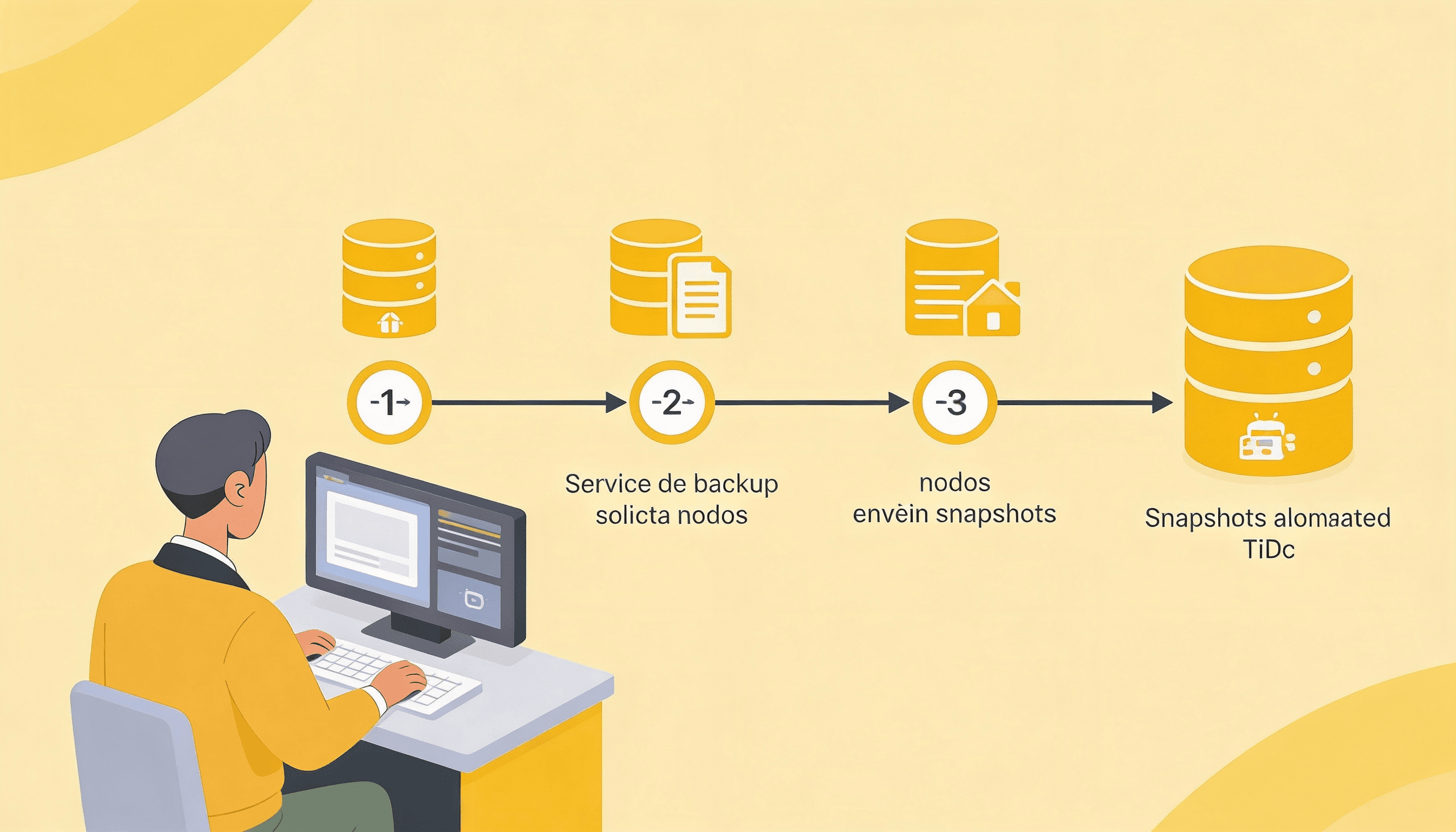
Operar Qdrant en producción requiere realizar backups periódicos para proteger los datos. Estos backups se generan a través de snapshots, que capturan el estado de los datos en un momento específico.
Esto dificulta garantizar consistencia a nivel de cluster y aumenta el riesgo de restauraciones parciales.
Para resolver este problema, los backups deben tratarse como una operación lógica única, aunque involucren múltiples nodos.

Gracias a esta coordinación, es posible restaurar el estado completo del cluster sin operaciones manuales ni combinaciones incorrectas de snapshots.
En escenarios reales, las condiciones del cluster pueden cambiar: menos nodos disponibles, pods reiniciados o recursos limitados. Para estos casos, el proceso de restauración permite consolidar múltiples shards en un solo nodo cuando es necesario. Una vez recuperados los datos, los shards pueden redistribuirse mediante resharding para volver a equilibrar el cluster. Esta flexibilidad reduce el tiempo de recuperación y mejora la disponibilidad del servicio.

La operación de bases de datos vectoriales en entornos distribuidos exige algo más que buen rendimiento: requiere estrategias sólidas de respaldo y recuperación que acompañen el crecimiento y la complejidad del sistema. Al implementar un enfoque de backup y restore coordinado a nivel de cluster.
En Meetlabs puede reducir la carga operativa, asegurar la consistencia de los datos y responder con mayor rapidez ante fallos o cambios en la infraestructura. Este tipo de diseño no solo fortalece la resiliencia técnica, sino que también permite que los equipos se enfoquen en crear y escalar soluciones de inteligencia artificial con mayor confianza y estabilidad.