En experimentos digitales, incluso con grandes volúmenes de datos, medir el impacto real de una campaña puede resultar difícil debido a la alta variabilidad en métricas como la conversión. Métodos tradicionales de A/B testing estiman el efecto promedio del tratamiento, pero pueden generar intervalos de confianza amplios cuando las tasas de conversión son bajas. Este artículo explica cómo el enfoque MLRATE (Machine Learning Regression-Adjusted Treatment Effect) combina aprendizaje automático con inferencia estadística para reducir la varianza en la estimación del efecto. Desde la perspectiva de analítica avanzada de Meetlabs, esta metodología permite mejorar la precisión experimental y fortalecer la toma de decisiones basada en datos.

En productos digitales, gran parte de las decisiones estratégicas se apoyan en experimentos controlados como el A/B testing. Equipos de producto, marketing o crecimiento utilizan estos experimentos para evaluar campañas publicitarias, cambios en interfaces o nuevas funcionalidades. Sin embargo, incluso con millones de usuarios, detectar efectos pequeños como un aumento de 0.5 % en conversión puede ser estadísticamente complejo. Las tasas de conversión suelen ser bajas y la variabilidad entre usuarios introduce ruido en la medición.
Aquí es donde metodologías como MLRATE ofrecen una evolución en la experimentación digital: combinan modelos predictivos con técnicas estadísticas tradicionales para reducir la varianza de la estimación y mejorar la precisión con la que se mide el impacto real de una intervención.
Los experimentos digitales enfrentan un desafío recurrente: la señal que se intenta medir suele ser pequeña en comparación con el ruido presente en los datos, esto genera situaciones en las que campañas o mejoras reales pueden pasar desapercibidas simplemente porque el experimento no tiene suficiente precisión estadística. Reducir la varianza de las estimaciones se convierte entonces en un objetivo clave para acelerar la toma de decisiones basada en evidencia.
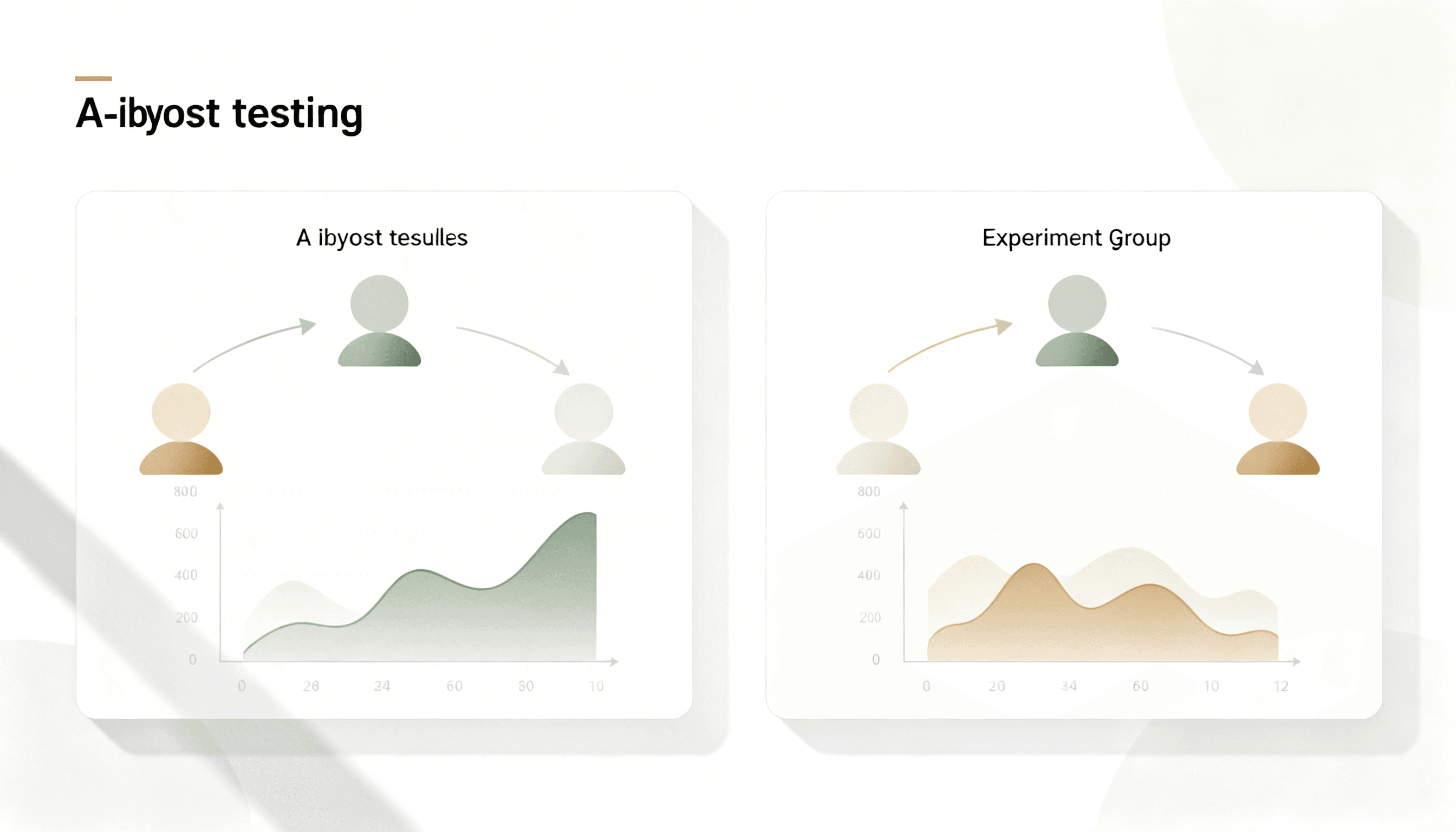
En un experimento A/B clásico se comparan dos grupos de usuarios: uno expuesto a una intervención (tratamiento) y otro que actúa como referencia (control). El objetivo es estimar la diferencia promedio en una métrica de interés, como la conversión o el tiempo de uso. Aunque el procedimiento es conceptualmente simple, la medición puede verse afectada por una gran variabilidad en el comportamiento de los usuarios. Diferencias en hábitos de navegación, historial de compras o contexto temporal introducen ruido en los resultados, esto genera varios efectos en la práctica:
En contextos de marketing digital, donde pequeños incrementos en conversión pueden generar grandes impactos financieros, mejorar la precisión de estas estimaciones resulta fundamental.
MLRATE propone mejorar la estimación del efecto experimental utilizando un modelo de aprendizaje automático que prediga el resultado esperado de cada usuario en función de sus características. El proceso combina dos componentes: un modelo predictivo y una regresión estadística ajustada. Primero se entrena un modelo capaz de estimar la probabilidad de conversión o el valor esperado del resultado. Posteriormente, esa predicción se utiliza como variable adicional dentro del modelo estadístico que calcula el efecto del tratamiento. El flujo general del método incluye:
En términos intuitivos, el modelo predictivo ayuda a explicar parte del comportamiento de los usuarios, permitiendo que la estimación del efecto experimental se concentre en el impacto real del tratamiento.

La clave del método está en aprovechar información adicional sobre el comportamiento esperado de los usuarios. Si un modelo puede predecir parcialmente la probabilidad de conversión, esa información puede utilizarse para explicar parte de la variabilidad observada en los datos.La reducción de varianza depende principalmente de la correlación entre el resultado real observado y la predicción generada por el modelo. Cuanto mayor sea esta correlación, mayor será la proporción de ruido que puede eliminarse del cálculo del efecto experimental, esto implica varias consecuencias prácticas:
De esta forma, el modelado predictivo se convierte en un complemento natural de la experimentación digital.

Para evaluar la efectividad del enfoque se aplicó el método a un conjunto de datos públicos de experimentos publicitarios con más de 580 000 usuarios. El dataset incluía información sobre exposición a anuncios, conversiones y variables contextuales como número de anuncios vistos o momentos de mayor interacción. Se entrenó un modelo predictivo utilizando técnicas de aprendizaje automático y posteriormente se aplicó el ajuste MLRATE para recalcular el efecto experimental. Los resultados mostraron una mejora clara en la precisión estadística:
Aunque la diferencia en el valor puntual puede parecer pequeña, la reducción del intervalo de confianza implica mayor seguridad al tomar decisiones basadas en el experimento.
MLRATE representa una evolución natural en la experimentación digital al combinar inferencia causal con modelos de aprendizaje automático. Este enfoque permite reducir la varianza en la estimación del efecto de campañas o funcionalidades, generando resultados estadísticos más precisos sin necesidad de aumentar significativamente el tamaño de los experimentos. Desde la perspectiva de analítica avanzada en Meetlabs, integrar este tipo de metodologías abre nuevas oportunidades para transformar datos en decisiones estratégicas más confiables. En un entorno donde pequeñas mejoras pueden generar grandes impactos de negocio, reducir la incertidumbre estadística se convierte en una ventaja competitiva real.