En este artículo exploramos cómo diseñar y operar una arquitectura de datos y Machine Learning pensada para entornos reales de producción, donde la escalabilidad, la disponibilidad y la recuperación ante fallos son tan importantes como la precisión del modelo. A través del uso de bases de datos vectoriales, arquitectura distribuida y un sistema de backups consistente a nivel de cluster, mostramos cómo pasar de soluciones frágiles y manuales a operaciones más confiables, automatizadas y alineadas con las necesidades del negocio.

En sistemas basados en Machine Learning, el mejorar la precisión de un modelo no siempre llevará a mejores resultados en cuestión a la productividad. Por pequeño que parezca un cambio técnico, puede tener efectos colaterales en tiempos de respuesta, uso de memoria o estabilidad operativa.
Nosotros, en Meetlabs, donde los modelos se utilizan para tomar mejores decisiones en tiempo real con una estructura, y entender que estos trade-offs es tan importante como mejorar las métricas
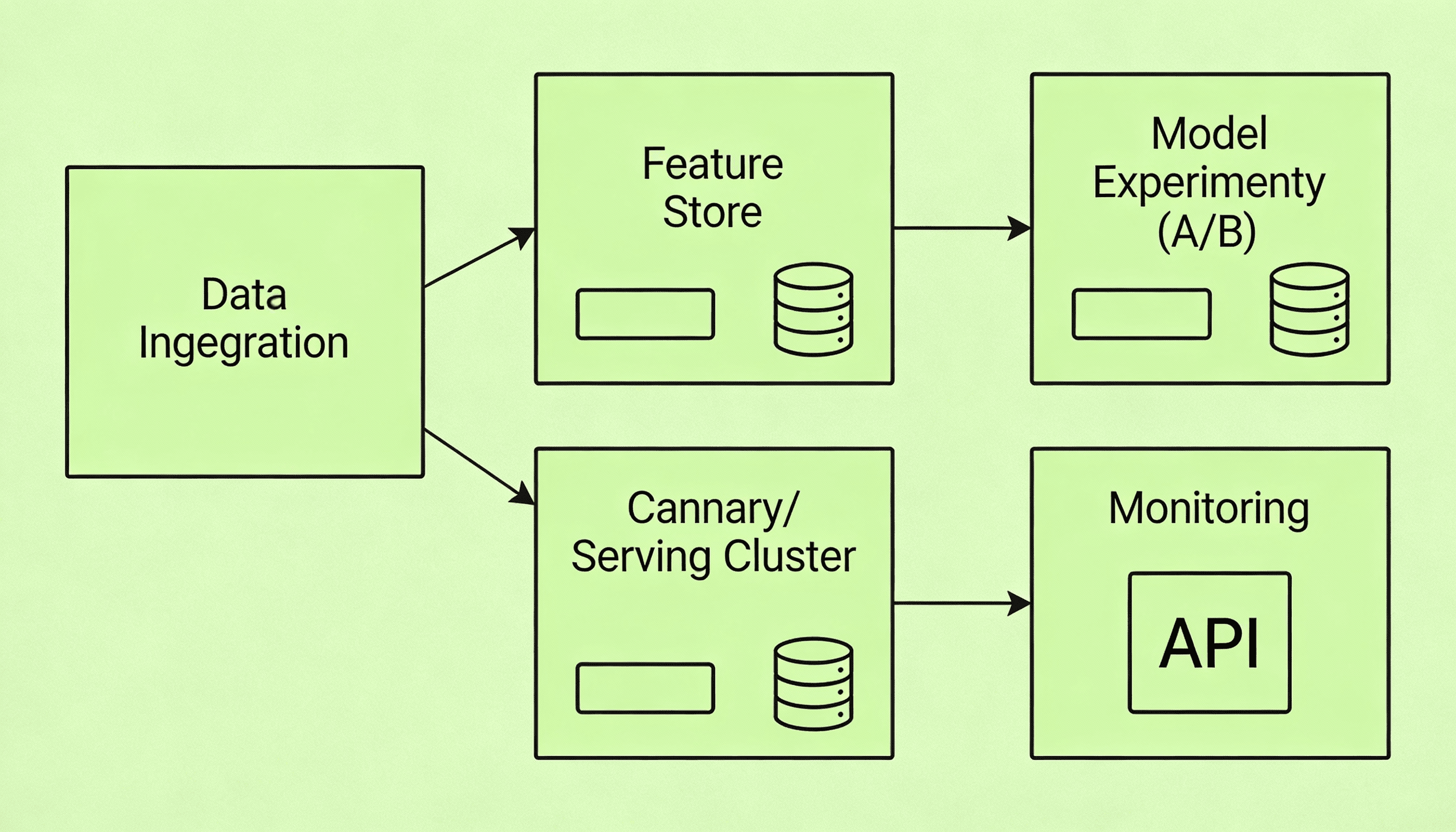
La predicción de CVR es una pieza central en muchos sistemas inteligentes: permite estimar la probabilidad de que un usuario complete una acción valiosa, como registrarse, comprar o interactuar con un producto. Estas predicciones se usan para optimizar decisiones automáticas que deben ejecutarse en milisegundos.
Por eso, cualquier cambio en la arquitectura del modelo debe evaluarse desde una perspectiva integral.
Para capturar patrones complejos del comportamiento de usuarios y contextos, los modelos utilizan embeddings: representaciones numéricas (vectores) que condensan información relevante de variables categóricas como usuarios, anunciantes o eventos.
En Meetlabs utilizamos modelos basados en Field-aware Factorization Machines (FFM), una arquitectura especialmente adecuada para datos grandes y dispersos, ya que ofrece un buen equilibrio entre precisión y velocidad de inferencia.
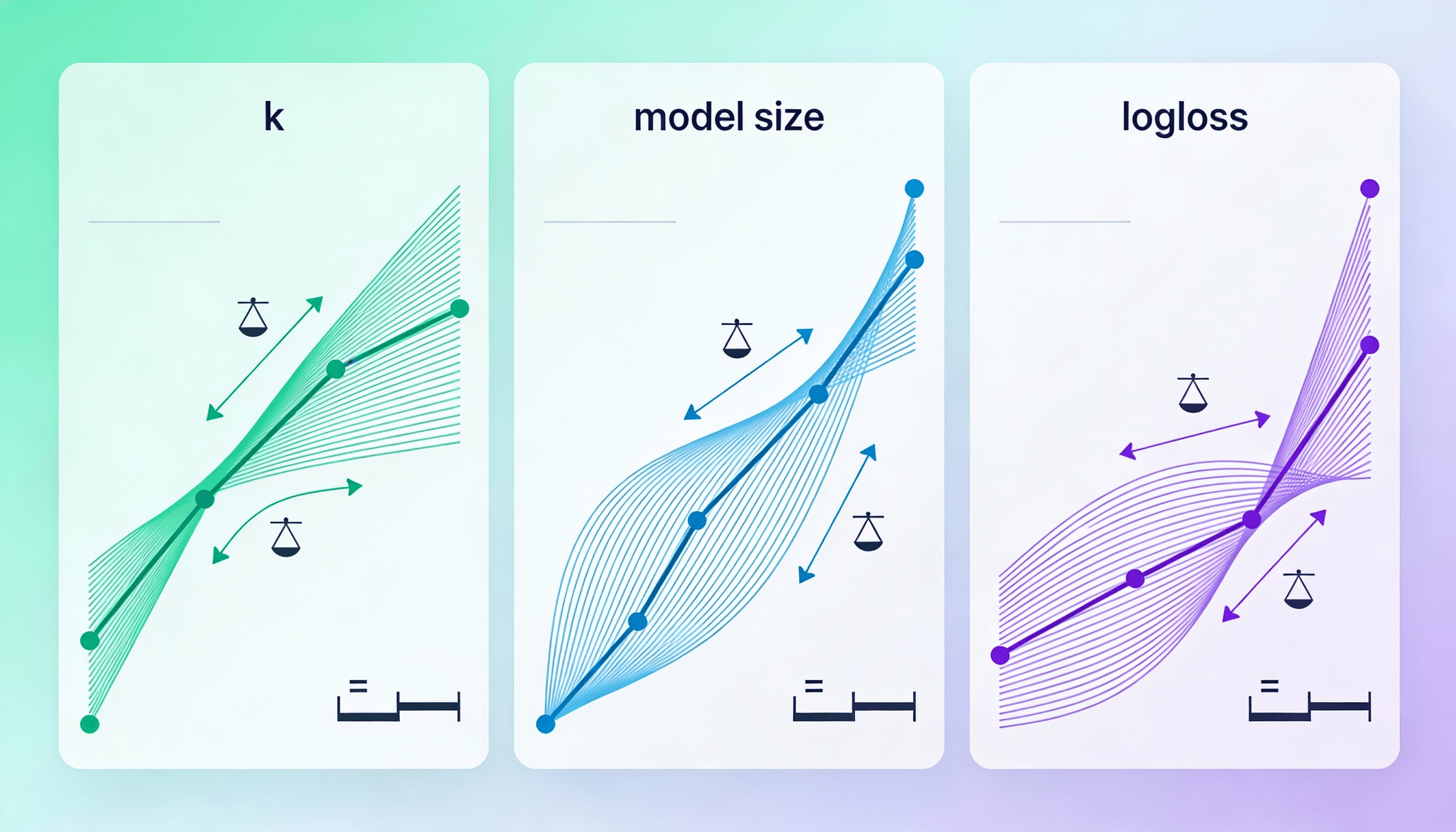
Dentro de los resultados claves del análisis técnico se permitió entender cómo las decisiones de arquitectura impactan directamente con el desempeño del sistema. Al optimizar la forma en que se almacenan y se consultan vectores, se ha logrado un equilibrio entre capacidad, velocidad y el consumo de recursos que permite operar modelos de IA en producción sin fricción.
El mayor valor del análisis fue comprender cómo una infraestructura bien diseñada, más allá de las métricas, reduce la complejidad operativa y mejora la confiabilidad del sistema. Esto ayudó a pasar de una gestión reactiva a una operación mucho más predecible y escalable.

El análisis del impacto de los embeddings en la predicción de CVR demuestra que, en sistemas de Machine Learning en producción, la mejor decisión no siempre es aumentar la complejidad del modelo.
En Meetlabs, este tipo de evaluaciones nos permite tomar decisiones informadas, equilibrando precisión, eficiencia y estabilidad operativa. Entender estos trade-offs es clave para construir sistemas de IA confiables, escalables y realmente útiles para el negocio.