In this article we explain how to design and implement a consistent backup and restore system for distributed databases used in AI products. Using a real case with Qdrant, we show how to group snapshots, orchestrate backups across multiple nodes, and ensure reliable restores even when cluster configuration changes. The approach targets teams building robust, scalable, fault-tolerant data infrastructure.

As companies adopt vector databases for use cases like semantic search, AI assistants, RAG, and recommendation systems, a key challenge arises: how to guarantee operational continuity as the system grows, becomes distributed, and experiences failures.
At Meetlabs we work with modern data architectures where availability, consistency, and scalability are non-negotiable. In this article we explain how to approach backup and restore for vector databases in distributed clusters, and how to design a solution that enables fast, consistent, and automated data recovery, even in failure scenarios.
When building AI-driven products, especially those that use embeddings—a recurring challenge appears: reliably handling large volumes of vector data. Texts, images, user behavior and other signals are transformed into numerical representations, in this case vectors that must be stored, searched, and filtered efficiently.
This is where vector databases come in. At Meetlabs, Qdrant is one of the technologies we use to enable similarity-search flows and Retrieval-Augmented Generation (RAG), increasingly common in modern AI systems.
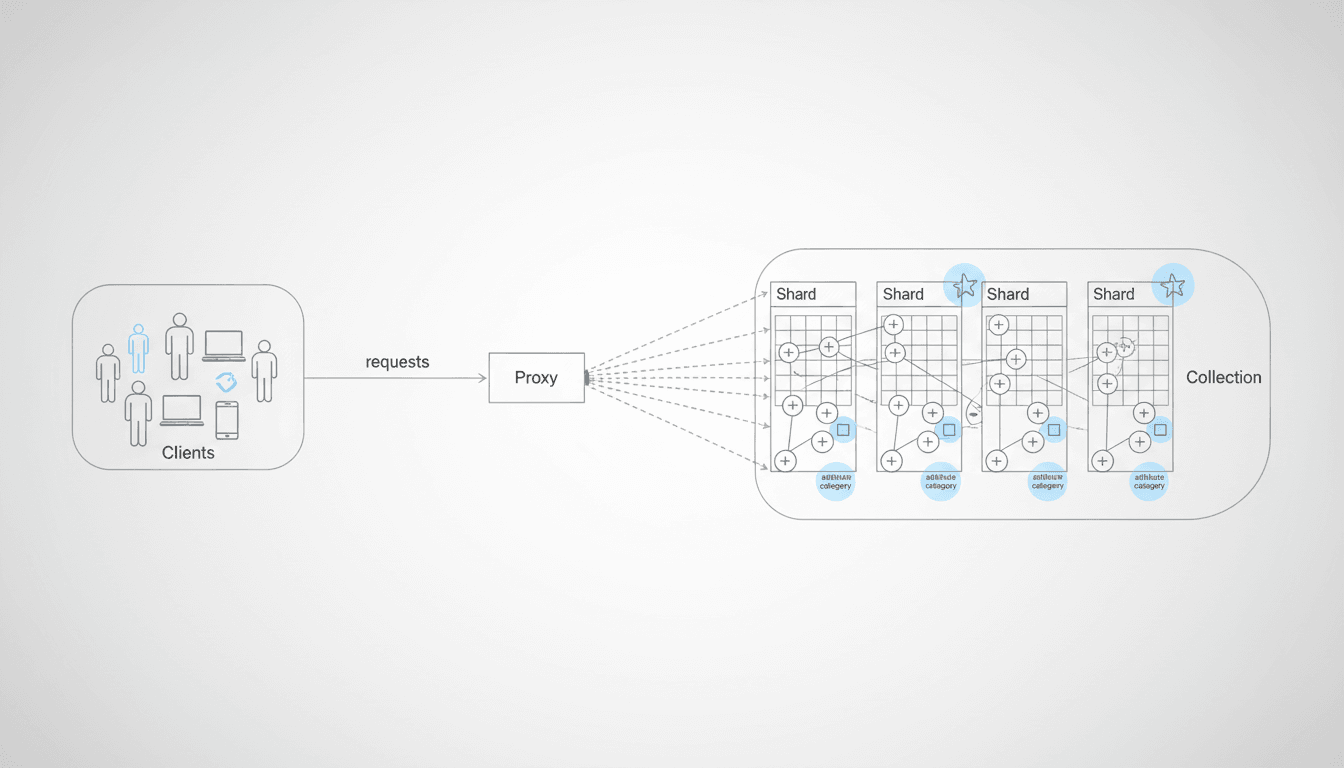
Qdrant is a vector database optimized for similarity search in high-dimensional spaces. Rather than working only with rows and columns, it focuses on vectors and the mathematical distance between them.
Logically, Qdrant structures data as follows:
A point combines:
This design allows combining semantic similarity searches with metadata-based filters, producing more precise results without losing context.
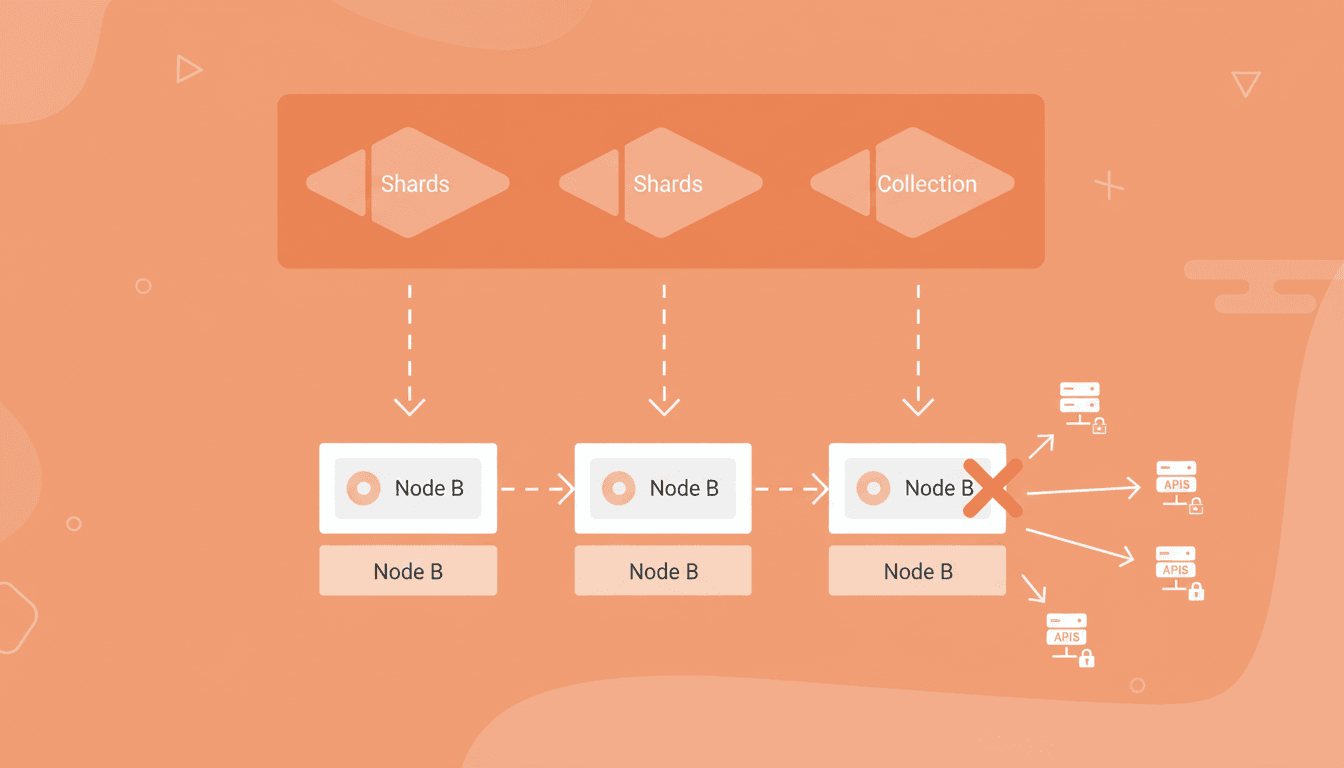
As data grows, Qdrant can operate in distributed mode. Collections are automatically partitioned into shards, which are distributed across different nodes using consistent hashing.
In modern environments, these nodes are often deployed as pods in Kubernetes, which adds flexibility but also introduces operational complexity when the number of nodes changes.
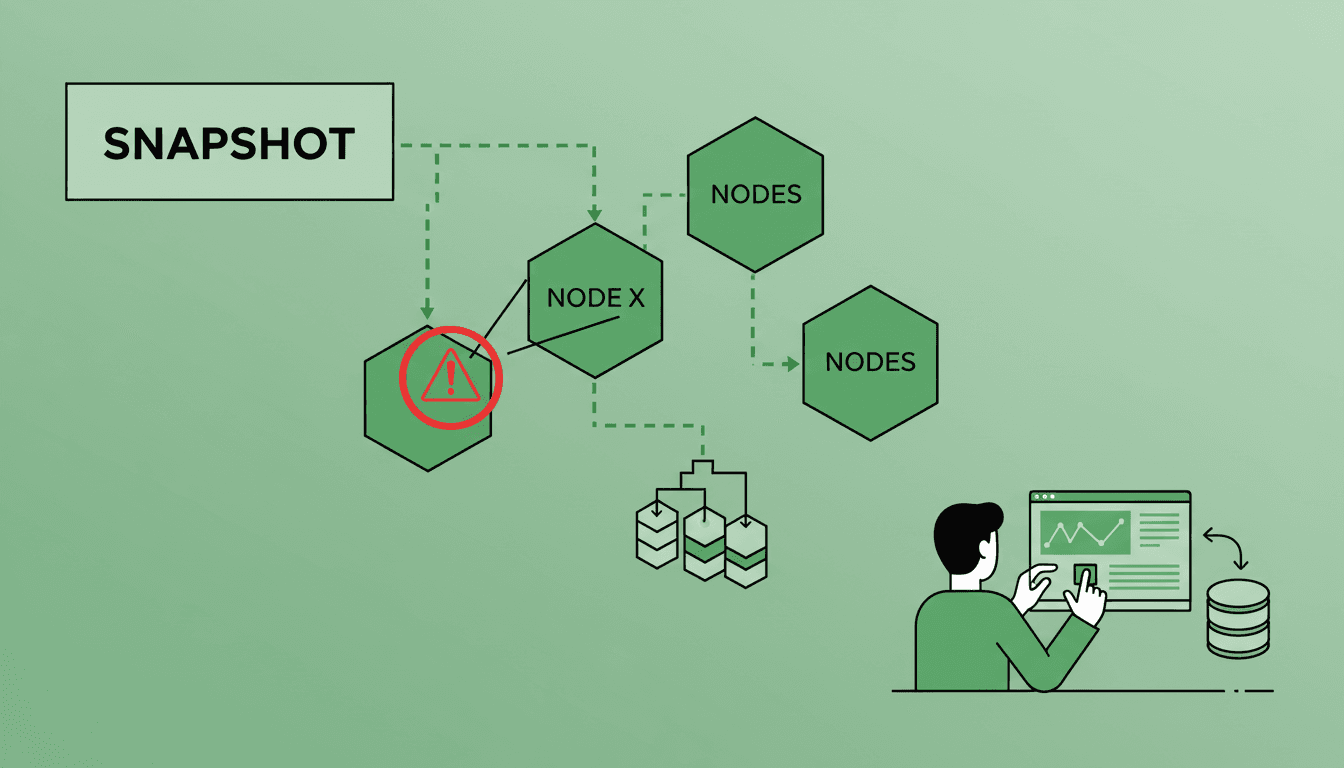
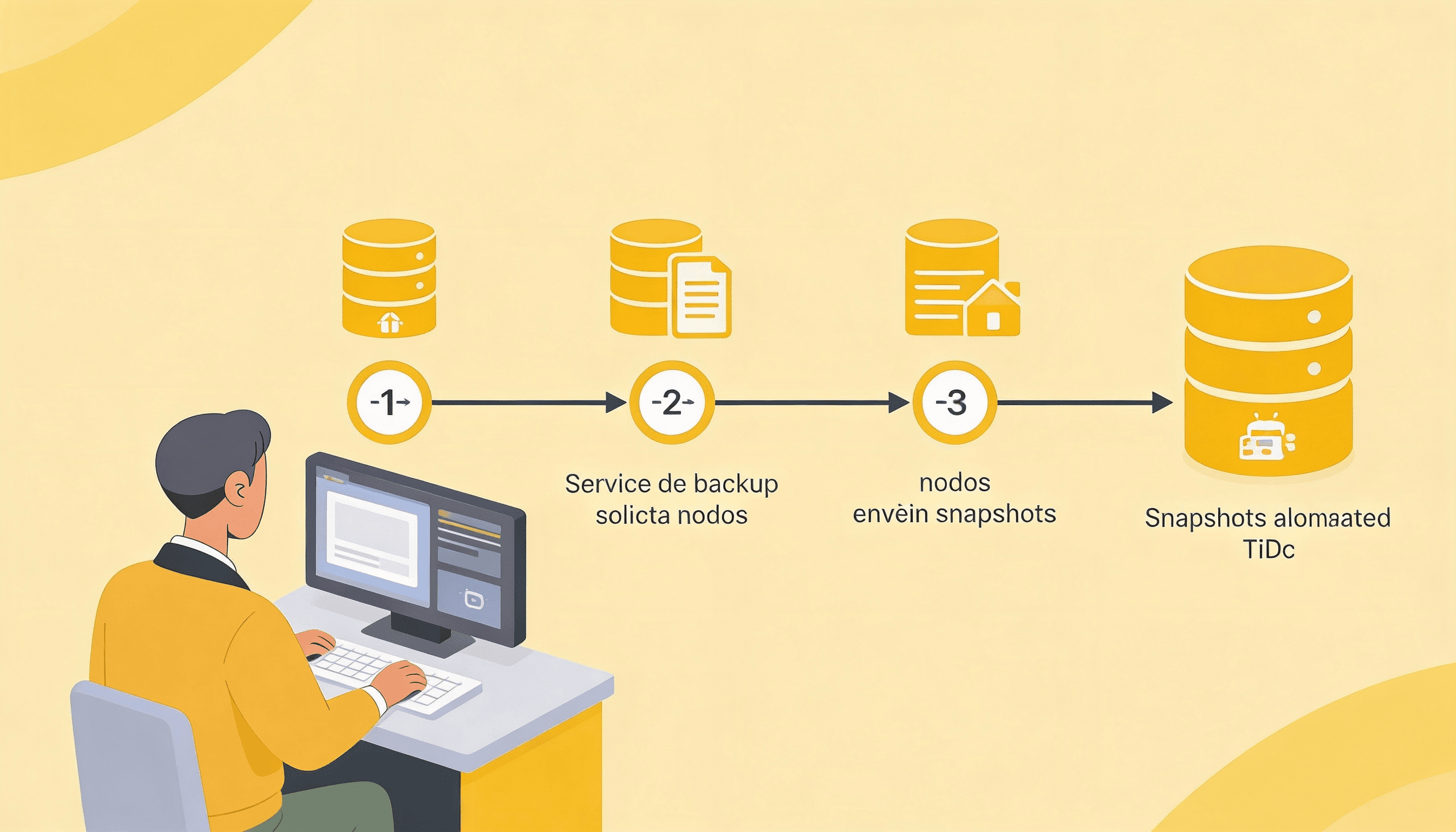
Running Qdrant in production requires periodic backups to protect the data. These backups are generated via snapshots that capture the state of the data at a specific moment.
This makes it difficult to guarantee cluster-level consistency and increases the risk of partial or inconsistent restores.
To solve this problem, backups must be treated as a single logical operation, even though they involve multiple nodes.

Thanks to this coordination, it is possible to restore the cluster’s full state without manual operations or incorrect combinations of snapshots.
In real scenarios, cluster conditions can change: fewer available nodes, restarted pods, or constrained resources. For these cases, the restore process allows consolidating multiple shards onto a single node when required. Once the data is recovered, shards can be redistributed via resharding to rebalance the cluster. This flexibility reduces recovery time and improves service availability.

Operating vector databases in distributed environments requires more than good performance: it requires robust backup and recovery strategies that grow with the system’s complexity. By implementing a cluster-coordinated backup and restore approach, Meetlabs can reduce operational burden, ensure data consistency, and respond faster to failures or infrastructure changes. Such a design not only strengthens technical resilience but also allows teams to focus on building and scaling AI solutions with greater confidence and stability.