This article explores how to build a minimal robotic dialogue system using an iPhone 12, Swift, the OpenAI Realtime API and DockKit. We analyze system architecture, audio processing, WebSocket session management, voice playback, facial animation, and practical mitigations for echo. We also reflect on the practical potential of low-cost robots for enterprise and home environments.

The field of LLM-based dialogue systems has evolved rapidly over the past year. Whereas early efforts focused on voice-dialogue fundamentals with generative AI, today we see a shift toward practical, production-ready applications particularly in enterprise contexts.
In this article we explore building a “dialogue robot” with concurrency and physical co-presence using:
The goal is to show that a functional interactive robotic system can be built with minimal investment.
The Realtime API supports:
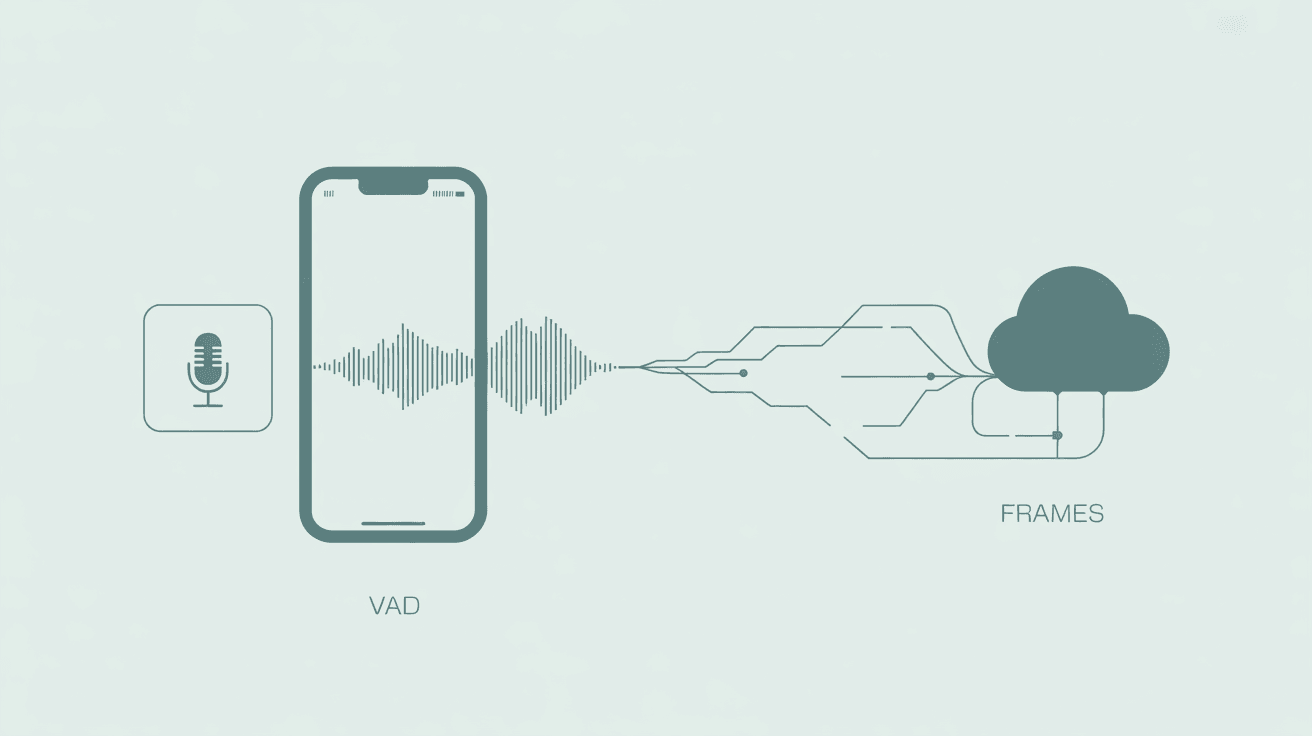
Captured microphone audio must be adapted before transmission. API requirements:
Therefore you must:
This step is critical to ensure stability and to avoid erratic behaviors such as incorrect responses or unexpected silences.
To play back audio received from the API you must:

Echo problem A common issue in robotic systems is the microphone capturing speaker output. In this prototype the problem was addressed by:
While not an advanced echo cancellation solution, this approach prevents the robot from starting conversations with itself.
DockKit is a motorized mount compatible with iPhone face tracking. Interestingly, direct use of the DockKit library was unnecessary. The approach that worked was:
This implies tracking may be managed at the OS level. The resulting robot:

Development of robotic dialogue systems has reached a point where practical implementations are viable, especially for enterprise use. Using an iPhone, Swift and the OpenAI Realtime API, you can build a functional interactive robot at a fraction of the cost of traditional robotic platforms. Technical challenges remain echo cancellation, robust speech recognition and stability in noisy environments but the cost-benefit ratio of this approach is highly attractive. Combining consumer devices with advanced generative AI may accelerate wider adoption of service robots in coming years.